共递归
目录
共递归
在计算机科学中,核心递归是一种与递归对偶的运算。 递归以分析方式工作,从基本案例开始处理数据并将其分解为更小的数据并重复直到到达基本案例,而核心递归以综合方式工作,从基本案例开始并构建它,迭代地生成从基本案例中进一步删除的数据 基本情况。 简而言之,核心递归算法使用它们自己产生的数据,当它们变得可用和需要时,一点一点地产生更多的数据。 一个类似但不同的概念是生成递归,它可能缺乏核心递归和递归固有的明确方向。
递归允许程序对任意复杂的数据进行操作,只要它们可以简化为简单数据(基本情况),核心递归允许程序生成任意复杂且可能无限的数据结构,例如流,只要它可以生成 从一系列有限步骤的简单数据(基本案例)。 在递归可能不会终止,永远不会到达基本状态的情况下,核心递归从基本状态开始,因此确定性地产生后续步骤,尽管它可能会无限期地进行(因此在严格评估下不会终止),或者它可能消耗超过它产生的和 从而变得没有生产力。 许多传统上被分析为递归的函数可以替代地,并且可以说更自然地,被解释为在给定阶段终止的核心递归函数,例如阶乘等递归关系。
共递归可以产生有限和无限数据结构作为结果,并且可以使用自引用数据结构。 共递归通常与惰性求值结合使用,只产生潜在无限结构的有限子集(而不是试图一次产生整个无限结构)。 共递归是函数式编程中一个特别重要的概念,其中 corecursion 和 codata 允许所有语言使用无限数据结构。
例子
共递归可以和递归对比理解,递归比较熟悉。 虽然 corecursion 主要用于函数式编程,但它可以使用命令式编程来说明,下面使用 Python 中的生成器工具完成。 在这些示例中,使用了局部变量,并强制性地(破坏性地)赋值,尽管这些在纯函数式编程的 corecursion 中不是必需的。 在纯函数式编程中,这些计算值不是分配给局部变量,而是形成一个不变的序列,并且先验值通过自引用访问(序列中较晚的值引用要计算的序列中较早的值)。 赋值只是在命令式范式中表达这一点,并明确指定计算发生的位置,这有助于阐明说明。
阶乘
递归的一个经典示例是计算阶乘,它由 0 递归定义! := 1 和 n! := n × (n – 1)!.
为了在给定输入上递归计算其结果,递归函数使用不同的(某种程度上更小的)输入调用自身(的副本),并使用此调用的结果来构造其结果。 递归调用做同样的事情,除非已经达到基本情况。 因此,调用堆栈在此过程中形成。 例如,为了计算 fac(3),它依次递归调用 fac(2)、fac(1)、fac(0)(结束堆栈),此时递归以 fac(0) = 1 终止,并且 然后堆栈以相反的顺序展开,结果在沿着调用堆栈返回到初始调用帧 fac(3) 的途中计算,该帧使用 fac(2) = 2 的结果计算最终结果为 3 × 2 = 3 × fac(2) =: fac(3) 最后返回 fac(3) = 6。在此示例中,函数返回单个值。
这个堆栈展开可以解释为递归地定义阶乘,作为一个迭代器,其中一个从 1 =: 0 的情况开始! {displaystyle 1=:0!} ,然后从这个起始值构造增加数字 1, 2, 3… ! ×(n+1)=:(n+1)! {displaystyle n!times (n+1)=:(n+1)!} 。
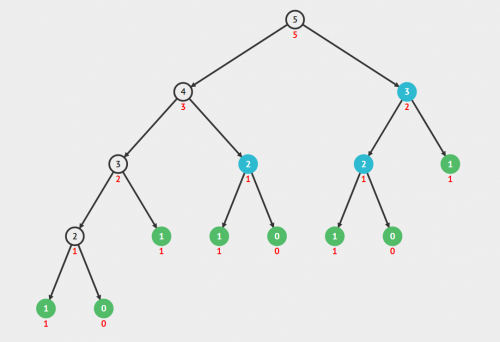
如此定义的核心递归算法产生所有阶乘的流。 这可以具体实现为生成器。 象征性地,注意计算下一个阶乘值需要跟踪 n 和 f(前一个阶乘值),这可以表示为:
n , f = ( 0 , 1 ) : ( n + 1 , f × ( n + 1 ) ) {displaystyle n,f=(0,1):(n+1,ftimes (n+1 ))}
或者在 Haskell 中,
((n,f) -> (n+1, f*(n+1))) `迭代` (0,1)
意思是,从 n , f = 0 , 1 {displaystyle n,f=0,1} 开始,在每一步中,下一个值计算为 n + 1 , f × ( n + 1 ) {displaystyle n+ 1,ftimes (n+1)} 。